

如何直接区分出Base16、Base32、Base64编码呢?
- ASCII 是用128(2^8)个字符,对二进制数据进行编码的方式
- Base64编码是用64(2^6)个字符,对二进制数据进行编码的方式
- Base32就是用32(2^5)个字符,对二进制数据进行编码的方式
- Base16就是用16(2^4)个字符,对二进制数据进行编码的方式
因此可以从编码字符的数量方面入手,对于base16,用于编码的字符只有:1-9,A-F ,只有简单的15个字符。 对于base32而言,编码字符有了明显改变,由base16的类型转变为了A-Z,2-7。 作为base系列中最完善的base64编码,是在base32的基础上,增加了”a-z,0,1,8,9,+,/“,以及特殊填充字符”=”。
Base64是一种基于64个(再加上作为填充字的"=",实际上是 65 个字符)可打印字符来表示二进制数据的编码算法。
Base64不是加密算法,其仅仅是一种编码方式,是一种公开的算法。
base64填充
Base64 编码将一个8位子节序列拆散为6位的片段,并为每个6位的片短分配一个字符,这个字符是Base-64字母表中的64个字符之一。
由于 2⁶ = 64 ,所以每 6 个比特为一个单元,对应某个可打印字符。3 个字节有 24 个比特,对应于 4 个 base64 单元,即 3 个字节可由 4 个可打印字符来表示。
标准的 base64每行为 76个字符。每行末尾添加一个回车换行符(\r\n)。
基于“=”的填充机制,我们可以通过观察Base64编码的字符串最后有几个“=”来判断最后一组24位中有几个“填充字节”。
转换过程如图:
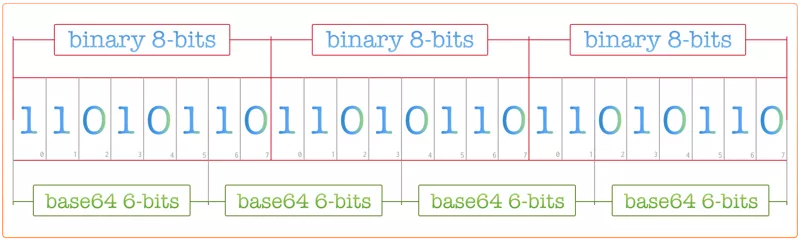
base64编码收到一个8位字节序列,将这个二进制序列流划分成6位的块。 二进制序列有时不能正好平均地分为6位的块,在这种情况下,就在序列末尾填充零位,使二进制序列的长度成为24的倍数(6和8的最小公倍数)。
对已填充的二进制进行编码时,任何完全填充(不包括原始数组中的位)的6位组都有特殊的第65个符号”=”表示。 如果6位组是部分填充的,就将填充位设置为0.
特别注意,Base64编码后的文本的长度总是4的倍数。
原始数据 二进制数据 Base64数据
a:a -- 011000 010011 101001 100001 -- YTph
a:aa -- 011000 010011 101001 100001 011000 01xxxx xxxxxx xxxxxx -- YTphYQ==
a:aaa -- 011000 010011 101001 100001 011000 010110 0001xx xxxxxx -- YTphYWE=
a:aaaa -- 011000 010011 101001 100001 011000 010110 000101 1000001 -- YTphYWFh
对于base系列的编码解码,可在下面的在线网站进行解码: base在线编码
65个字符
- 大写字母 A-Z 26个
- 小写字母 a-z 26个
- 数字 0-9 10个
- 符号 "+" 1个
- 符号 "/" 1个
- 填充字 "="
Base64 常用于在处理文本数据的场合,表示、传输、存储一些二进制数据,包括 MIME 的电子邮件及 XML 的一些复杂数据。在 MIME 格式的电子邮件中,base64 可以用来将二进制的字节序列数据编码成 ASCII 字符序列构成的文本。使用时,在传输编码方式中指定 base64。
所以说它本质上是一种将二进制数据转成文本数据的方案。
缺点
Base64编码的缺点是传输效率会降低,因为它把原始数据的长度增加了1/3。
如果把Base64的64个字符编码表换成32个、48个或者58个,就可以使用Base32编码,Base48编码和Base58编码。 字符越少,编码的效率就会越低。
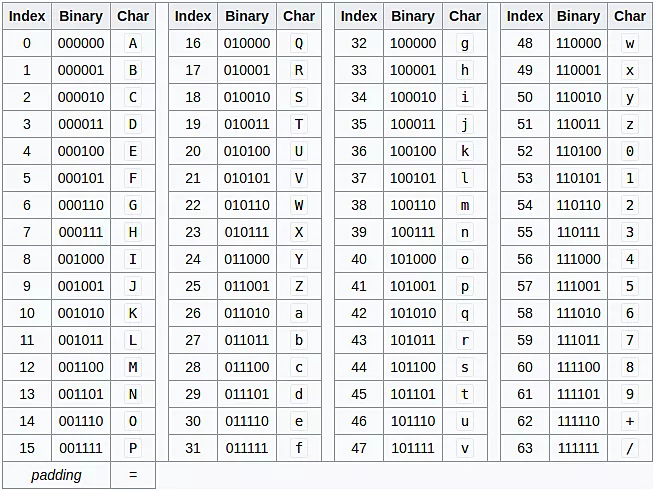
Base64码表
可以看到从0到63的每个数字都对应一个上面的一个字符。
代码样例
Java
public static void main(String[] args) {
baseLen3();
baseLenMore();
urlEncoder();
}
private static void baseLen3() {
byte[] input = new byte[] { (byte) 0xe4, (byte) 0xb8, (byte) 0xad };
String b64encoded = Base64.getEncoder().encodeToString(input);
System.out.println(b64encoded);
Preconditions.checkArgument(
StringUtils.equals("5Lit", b64encoded), "不符合期望");
byte[] output = Base64.getDecoder().decode(b64encoded);
String rs = Arrays.toString(output);
System.out.println(rs); // [-28, -72, -83]
Preconditions.checkArgument(
StringUtils.equals("[-28, -72, -83]", rs), "不符合期望");
}
private static void baseLenMore() {
String source = "张三目前在观看BBC纪录片:《海洋世界》.";
byte[] input = source.getBytes();
// 编码
String b64encoded = Base64.getEncoder().encodeToString(input);
// Base64编码的时候可以用withoutPadding()去掉=
String b64encoded2 = Base64.getEncoder().withoutPadding().encodeToString(input);
System.out.println(b64encoded);
Preconditions.checkArgument(
StringUtils.equals(b64encoded, "5byg5LiJ55uu5YmN5Zyo6KeC55yLQkJD57qq5b2V54mH77ya44CK5rW35rSL5LiW55WM44CLLg=="), "不符合期望");
System.out.println(b64encoded2);
// 解码
byte[] output = Base64.getDecoder().decode(b64encoded2);
String rs = new String(output);
System.out.println(rs);
Preconditions.checkArgument(
StringUtils.equals(source, rs), "不符合期望");
}
/**
* 因为标准的Base64编码会出现+、/和=,所以不适合把Base64编码后的字符串放到URL中。
*
* 一种针对URL的Base64编码可以在URL中使用的Base64编码,它仅仅是把+变成-,/变成_:
*/
private static void urlEncoder() {
String source = "张三目前在观看BBC纪录片:https://海洋世界.com.";
byte[] input = source.getBytes();
// 编码
String b64encoded = Base64.getUrlEncoder().encodeToString(input);
System.out.println(b64encoded);
Preconditions.checkArgument(
StringUtils.equals(b64encoded, "5byg5LiJ55uu5YmN5Zyo6KeC55yLQkJD57qq5b2V54mH77yaaHR0cHM6Ly_mtbfmtIvkuJbnlYwuY29tLg=="), "不符合期望");
// 解码
byte[] output = Base64.getUrlDecoder().decode(b64encoded);
String rs = new String(output);
System.out.println(rs);
Preconditions.checkArgument(
StringUtils.equals(source, rs), "不符合期望");
}
JavaScript(CryptoJS)
// 引用 crypto-js 加密模块
var CryptoJS = require('crypto-js')
function base64Encode() {
var srcs = CryptoJS.enc.Utf8.parse(text);
var encodeData = CryptoJS.enc.Base64.stringify(srcs);
return encodeData
}
function base64Decode() {
var srcs = CryptoJS.enc.Base64.parse(encodeData);
var decodeData = srcs.toString(CryptoJS.enc.Utf8);
return decodeData
}
var text = "I love Python!"
var encodeData = base64Encode()
var decodeData = base64Decode()
console.log("Base64 编码: ", encodeData)
console.log("Base64 解码: ", decodeData)
// Base64 编码: SSBsb3ZlIFB5dGhvbiE=
// Base64 解码: I love Python!
Rust
fn main() {
// 原始数据
let data = "Hello, World!";
// 将数据编码为 BASE64
let encoded = base64::encode(data);
println!("Encoded: {}", encoded);
// 解码 BASE64 数据
match base64::decode(&encoded) {
Ok(decoded) => {
match String::from_utf8(decoded) {
Ok(decoded_string) => {
println!("Decoded: {}", decoded_string);
}
Err(e) => println!("Error decoding string: {}", e),
}
}
Err(e) => println!("Error decoding base64: {}", e),
}
}
Python
import base64
def base64_encode(text):
encode_data = base64.b64encode(text.encode())
return encode_data
def base64_decode(encode_data):
decode_data = base64.b64decode(encode_data)
return decode_data
if __name__ == '__main__':
text = 'I love Python!'
encode_data = base64_encode(text)
decode_data = base64_decode(encode_data)
print('Base64 编码:', encode_data)
print('Base64 解码:', decode_data)
# Base64 编码:b'SSBsb3ZlIFB5dGhvbiE='
# Base64 解码:b'I love Python!'
更多的Base编码
除了以上的三种编码外,base系列还有其他的几种: base58,base85,base91,base92,base128。
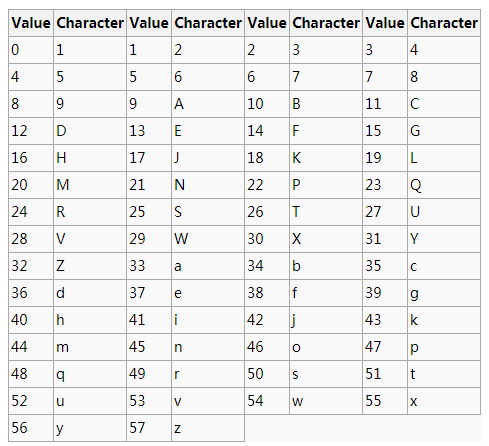
Base58
- 在Base64的基础上去掉了比较容易混淆的字符
- Base58中不含Base64中的数字 0 ,大写字母 O ,小写字母 l ,大写字母 I ,以及 “+” 和 “/” 两个字符。
- 无法用整字节来转换表示Base58,所以开销会比64和16大得多,但是利于展示地址。
Base58的应用:比特币、Monero、Ripple、Flickr。
Base58的设计目的? Base58编码,为比特币比特币钱包地址设计的。
- 避免混淆,在某些字体下,数字0和字母大写O,以及字母大写I和字母小写l会非常相似。
- Base64编码中包含"+"和"/",非字母或数字的字符串作为帐号较难被接受。
- 在邮件系统中,使用字符和数字的组合,不容易换行。
- 双击可以选中整个字符串。
Base58 代码样例
import java.util.Arrays;
public class Base58 {
// Base58编码表
public static final char[] ALPHABET = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz".toCharArray();
private static final char ENCODED_ZERO = ALPHABET[0];
private static final int[] INDEXES = new int[128];
static {
Arrays.fill(INDEXES, -1);
for (int i = 0; i < ALPHABET.length; i++) {
INDEXES[ALPHABET[i]] = i;
}
}
// Base58 编码
public static String encode(byte[] input) {
if (input.length == 0) {
return "";
}
// 统计前导0
int zeros = 0;
while (zeros < input.length && input[zeros] == 0) {
++zeros;
}
// 复制一份进行修改
input = Arrays.copyOf(input, input.length);
// 最大编码数据长度
char[] encoded = new char[input.length * 2];
int outputStart = encoded.length;
// Base58编码正式开始
for (int inputStart = zeros; inputStart < input.length;) {
encoded[--outputStart] = ALPHABET[divmod(input, inputStart, 256, 58)];
if (input[inputStart] == 0) {
++inputStart;
}
}
// 输出结果中有0,去掉输出结果的前端0
while (outputStart < encoded.length && encoded[outputStart] == ENCODED_ZERO) {
++outputStart;
}
// 处理前导0
while (--zeros >= 0) {
encoded[--outputStart] = ENCODED_ZERO;
}
// 返回Base58
return new String(encoded, outputStart, encoded.length - outputStart);
}
public static byte[] decode(String input) {
if (input.length() == 0) {
return new byte[0];
}
// 将BASE58编码的ASCII字符转换为BASE58字节序列
byte[] input58 = new byte[input.length()];
for (int i = 0; i < input.length(); ++i) {
char c = input.charAt(i);
int digit = c < 128 ? INDEXES[c] : -1;
if (digit < 0) {
String msg = "Invalid characters,c=" + c;
throw new RuntimeException(msg);
}
input58[i] = (byte) digit;
}
// 统计前导0
int zeros = 0;
while (zeros < input58.length && input58[zeros] == 0) {
++zeros;
}
// Base58 编码转 字节序(256进制)编码
byte[] decoded = new byte[input.length()];
int outputStart = decoded.length;
for (int inputStart = zeros; inputStart < input58.length;) {
decoded[--outputStart] = divmod(input58, inputStart, 58, 256);
if (input58[inputStart] == 0) {
++inputStart;
}
}
// 忽略在计算过程中添加的额外超前零点。
while (outputStart < decoded.length && decoded[outputStart] == 0) {
++outputStart;
}
// 返回原始的字节数据
return Arrays.copyOfRange(decoded, outputStart - zeros, decoded.length);
}
// 进制转换代码
private static byte divmod(byte[] number, int firstDigit, int base, int divisor) {
int remainder = 0;
for (int i = firstDigit; i < number.length; i++) {
int digit = (int) number[i] & 0xFF;
int temp = remainder * base + digit;
number[i] = (byte) (temp / divisor);
remainder = temp % divisor;
}
return (byte) remainder;
}
public static void main(String[] args) {
byte[] data = new byte[] {0,0,58,0,0,59};
String dataStr = Base58.encode(data);
System.out.println("Base58编码后:"+dataStr);
byte[] ndata = Base58.decode(dataStr);
for (byte b : ndata) {
System.out.println(b);
}
}
}
评论区