

Clickhouse
ClickHouse OLAP列式数据库。
- 支持完备的SQL操作
- 列式存储与数据压缩
- 向量化执行引擎
- 关系型模型(与传统数据库类似)
- 丰富的表引擎
- 并行处理
- 在线查询
- 数据分片
ClickHouse目前是基于ZooKeeper来存储元数据,包含分布式的DDL、表和数据Part信息,从元数据丰富程度来说稍弱,因为存储了大量细粒度的文件信息,导致ZooKeeper经常出现性能瓶颈.
ClickHouse依赖Zookeeper来实现数据的高可用,Zookeeper带来额外的运维复杂性的同时也有性能问题。
- 不支持事务。
- 不支持二级索引(当然用了跳数索引的算法做了补充替代实现)
- 聚合结果必须小于一台机器的内存大小:不是大问题
- 不擅长按行删除数据(虽然支持,但缺少完整的Update/Delete操作)
- 不支持窗口功能;
- 元数据管理需要人为干预。
ClickHouse架构
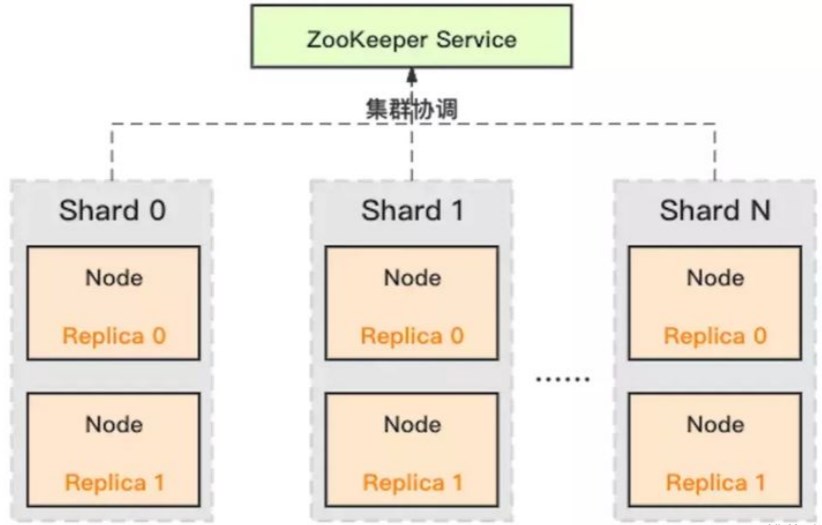
ClickHouse 采用典型的分组式的分布式架构,
其中:
- Shard: 集群内划分为多个分片或分组(Shard 0 … Shard N),通过 Shard的线性扩展能力,支持海量数据的分布式存储计算。
- Node: 每个 Shard 内包含一定数量的节点(Node,即进程),同一 Shard 内的节点互为副本,保障数据可靠。ClickHouse 中副本数可按需建设,且逻辑上不同 Shard 内的副本数可不同。
- ZooKeeper Service: 集群所有节点对等, 节点间通过 ZooKeeper 服务进行分布式协调 。
ClickHouse 有哪些应用场景?
- 绝大多数请求都是用于读访问的;
- 数据需要以大批次(大于 1000 行)进行更新,而不是单行更新;
- 数据只是添加到数据库,没有必要修改;
- 读取数据时,会从数据库中提取出大量的行,但只用到一小部分列;
- 表很“宽”,即表中包含大量的列;
- 查询频率相对较低(通常每台服务器每秒查询数百次或更少);
- 在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行);
- 不需要事务;
- 数据一致性要求较低;
- 每次查询中只会查询一个大表。除了一个大表,其余都是小表;
- 查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存。
评论区