

SQL解析具体包括了五个步骤:词法分析,语法分析,生成单机逻辑计划,生成分布式逻辑计划,生成物理执行计划。

一个简单的查询SQL在Doris的解析实现:
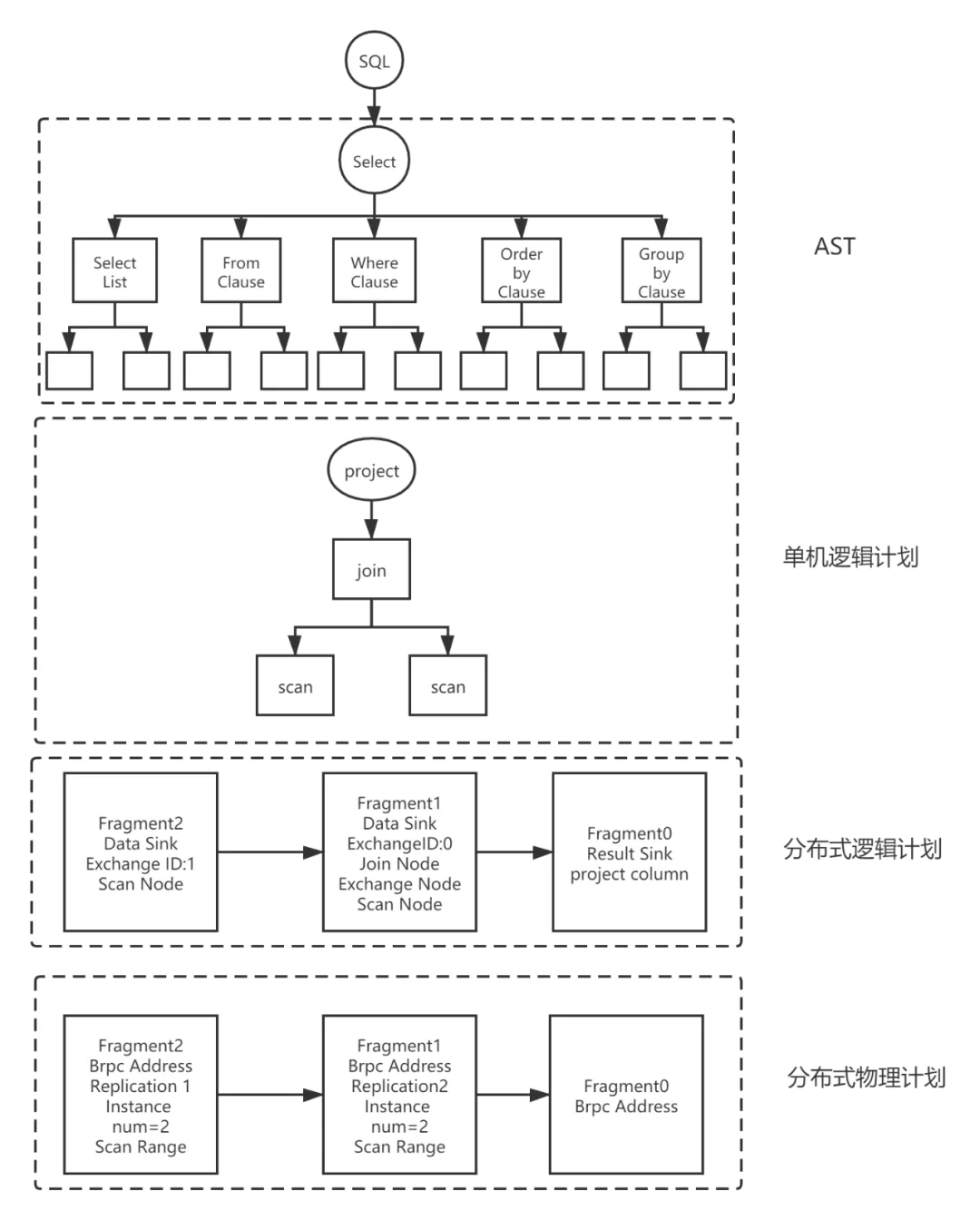
AST
Parse阶段
词法分析采用jflex技术,语法分析采用java cup parser技术,最后生成抽象语法树(Abstract Syntax Tree)AST.
这些都是现有的、成熟的技术.
Analyze阶段
对Parse阶段生成的抽象语法树AST进行一些前期的处理和语义分析,为生成单机逻辑计划做准备。
对于查询类型的SQL,包含以下几项重要工作
- 元信息的识别和解析
识别和解析sql中涉及的 Cluster, Database, Table, Column 等元信息,确定需要对哪个集群的哪个数据库的哪些表的哪些列进行计算。 - SQL 的合法性检查
窗口函数不能 DISTINCT,投影列是否有歧义,where语句中不能含有grouping操作等。 - SQL 简单重写
比如将 select * 扩展成 select 所有列,count distinct转成bitmap或者hll函数等。 - 函数处理
检查sql中包含的函数和系统定义的函数是否一致,包括参数类型,参数个数等。 - Table 和 Column 的别名处理
- 类型检查和转换
例如二元表达式两边的类型不一致时,需要对其中一个类型进行转换(BIGINT 和 DECIMAL 比较,BIGINT 类型需要 Cast 成 DECIMAL)。
RBO 优化器
对AST 进行analyze后,会再进行一次rewrite操作,进行精简或者是转成统一的处理方式。
目前rewrite的算法是基于规则的方式,针对AST的树状结构,自底向上,应用每一条规则进行重写。
如果重写后,AST有变化,则再次进行analyze和rewrite,直到AST无变化为止。
此处会存在一些RBO优化器的实现。
例如:常量表达式的化简:1 + 1 + 1 重写成 3,1 > 2 重写成 Flase 等。
将一些语句转成统一的处理方式,比如将 where in, where exists 重写成 semi join, where not in,
where not exists 重写成 anti join。
生成单机逻辑Plan阶段
这部分工作主要是根据AST抽象语法树生成代数关系,也就是俗称的算子数。树上的每个节点都是一个算子,代表着一种操作。
如下图所示,
ScanNode代表着对一个表的扫描操作,将一个表的数据读出来。
HashJoinNode代表着join操作,小表在内存中构建哈希表,遍历大表找到连接键相同的值。
Project表示投影操作,代表着最后需要输出的列,图7表示只用输出citycode这一列。

在生成代数关系时,将投影列和查询条件尽可能放到扫描操作时执行。如果不进行优化,生成的关系代数下发到存储中执行的代价非常高。
这个阶段的主要工作
- Slot 物化
确定一个表达式对应的列需要 Scan 和计算,比如聚合节点的聚合函数表达式和 Group By 表达式需要进行物化。 - 投影下推
BE 在 Scan 时只会 Scan 必须读取的列。 - 谓词下推
在满足语义正确的前提下将过滤条件尽可能下推到 Scan 节点。 - 分区,分桶裁剪
根据过滤条件中的信息,确定需要扫描哪些分区,哪些桶的tablet。 - Join Reorder
对于 Inner Join, Doris 会根据行数调整表的顺序,将大表放在前面。 - Sort + Limit 优化成 TopN
对于order by limit语句会转换成TopN的操作节点,方便统一处理。 - MaterializedView 选择
会根据查询需要的列,过滤,排序和 Join 的列,行数,列数等因素选择最佳的物化视图。
下图展示了优化的示例,Doris是在生成关系代数的过程中优化,边生成边优化。
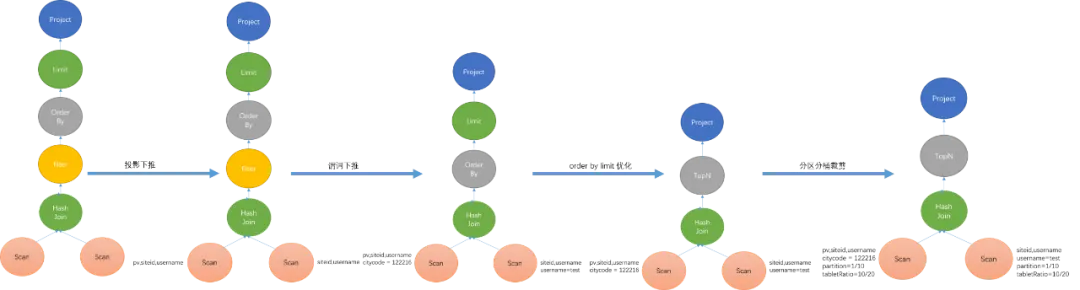
生成分布式Plan阶段
这个步骤的主要目标是最大化并行度和数据本地化。
根据分布式环境,拆成分布式PlanFragment树(PlanFragment用来表示独立的执行单元),
一个表的数据分散地存储在多台主机上,可以让一些计算并行。
主要方法是将能够并行执行的节点拆分出去单独建立一个PlanFragment,用ExchangeNode代替被拆分出去的节点,用来接收数据。
拆分出去的节点增加一个DataSinkNode,用来将计算之后的数据传送到ExchangeNode中,做进一步的处理。
这一步采用递归的方法,自底向上,遍历整个PlanNode树,然后给树上的每个叶子节点创建一个PlanFragment,
如果碰到父节点,则考虑将其中能够并行执行的子节点拆分出去,父节点和保留下来的子节点组成一个parent PlanFragment。
拆分出去的子节点增加一个父节点DataSinkNode组成一个child PlanFragment,child PlanFragment指向parent PlanFragment。
这样就确定了数据的流动方向。
支持的4种join算法
broadcast join,hash partition join,colocate join,bucket shuffle join。
- broadcast join
将小表发送到大表所在的每台机器,然后进行hash join操作。
当一个表扫描出的数据量较少时,计算broadcast join的cost,通过计算比较hash partition的cost,来选择cost最小的方式。 - hash partition join
当两张表扫描出的数据都很大时,一般采用hash partition join。
它遍历表中的所有数据,计算key的哈希值,然后对集群数取模,选到哪台机器,就将数据发送到这台机器进行hash join操作。 - colocate join
两个表在创建的时候就指定了数据分布保持一致,那么当两个表的join key与分桶的key一致时,就会采用colocate join算法。
由于两个表的数据分布是一样的,那么hash join操作就相当于在本地,不涉及到数据的传输,极大提高查询性能。 - bucket shuffle join
当join key是分桶key,并且只涉及到一个分区时,就会优先采用bucket shuffle join算法。
由于分桶本身就代表了数据的一种切分方式,所以可以利用这一特点,只需将右表对左表的分桶数hash取模,
这样只需网络传输一份右表数据,极大减少了数据的网络传输,如下图所示。
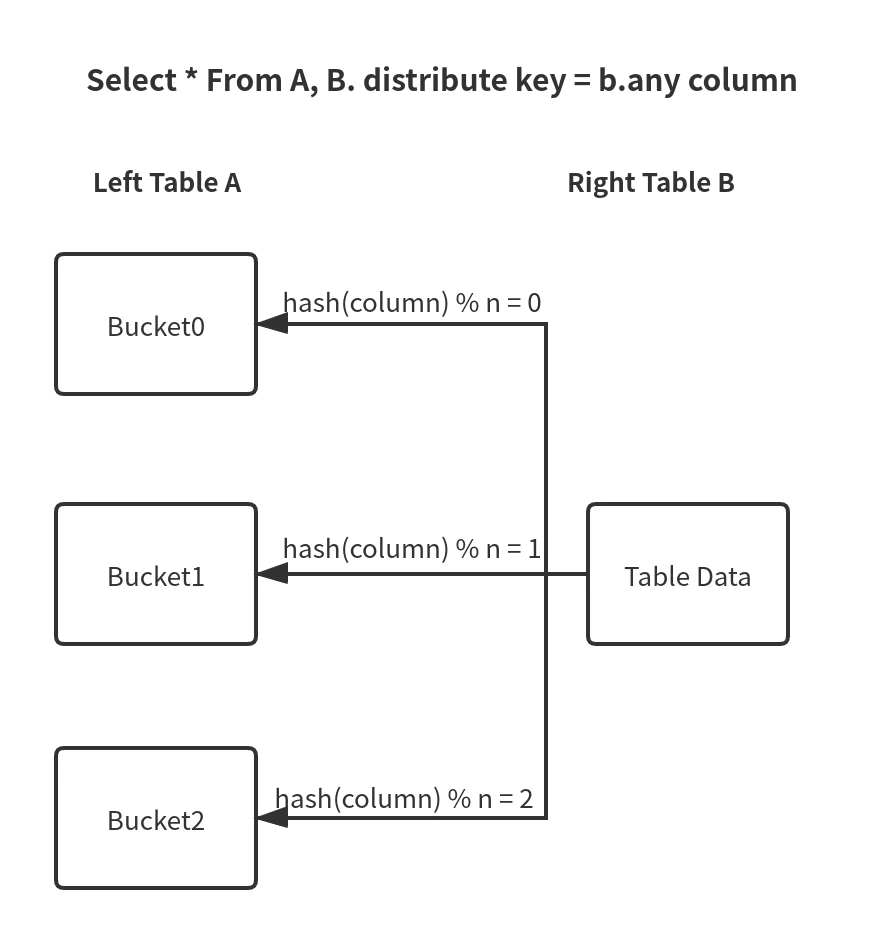
从单机计划到分布式计划
下图是两个表的join操作转换成PlanFragment树之后的示例,一共生成了3个PlanFragment。最终数据的输出通过ResultSinkNode节点。
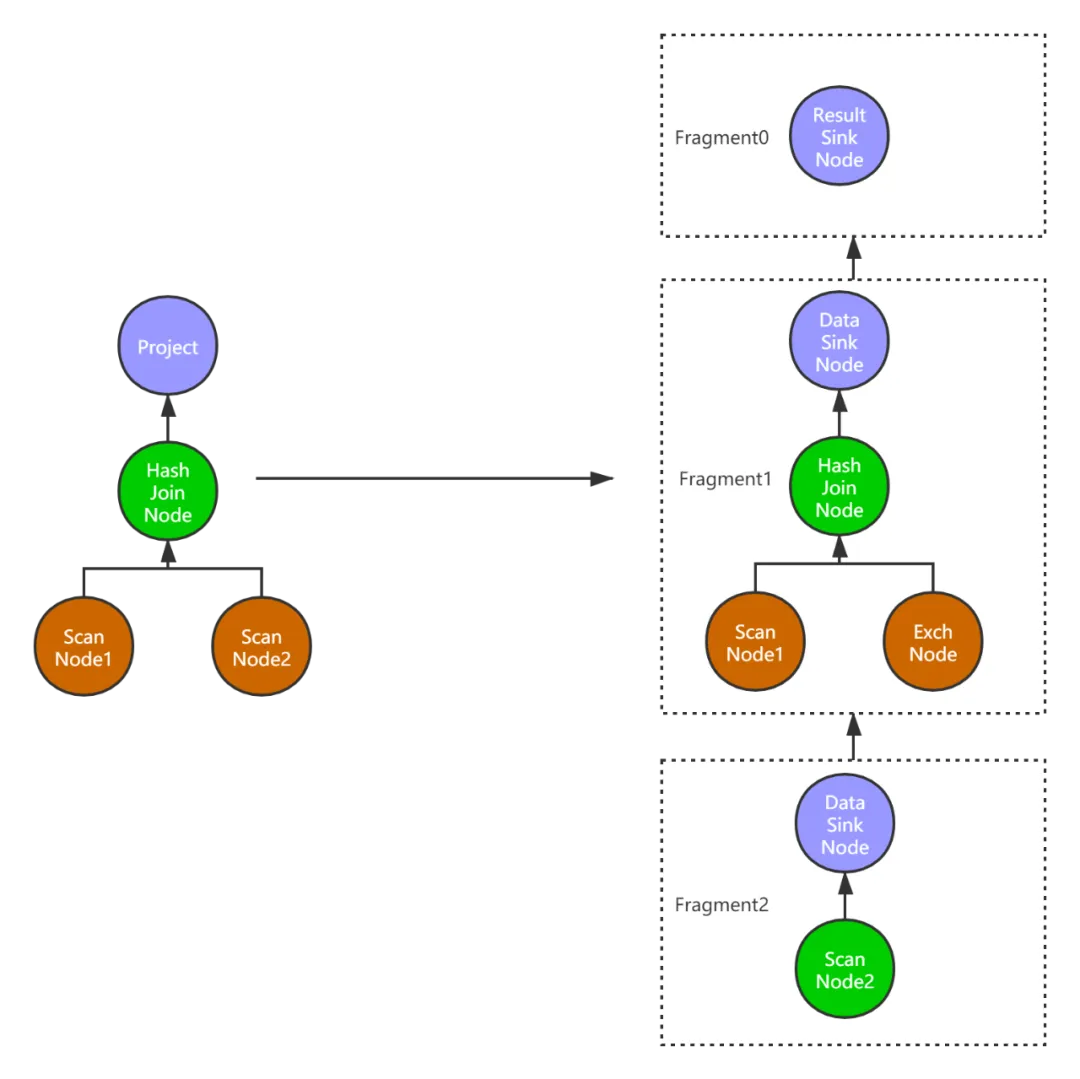
HashJoinNode
下图展示了带有 HashJoinNode 的单机逻辑计划创建分布式逻辑计划的核心流程。
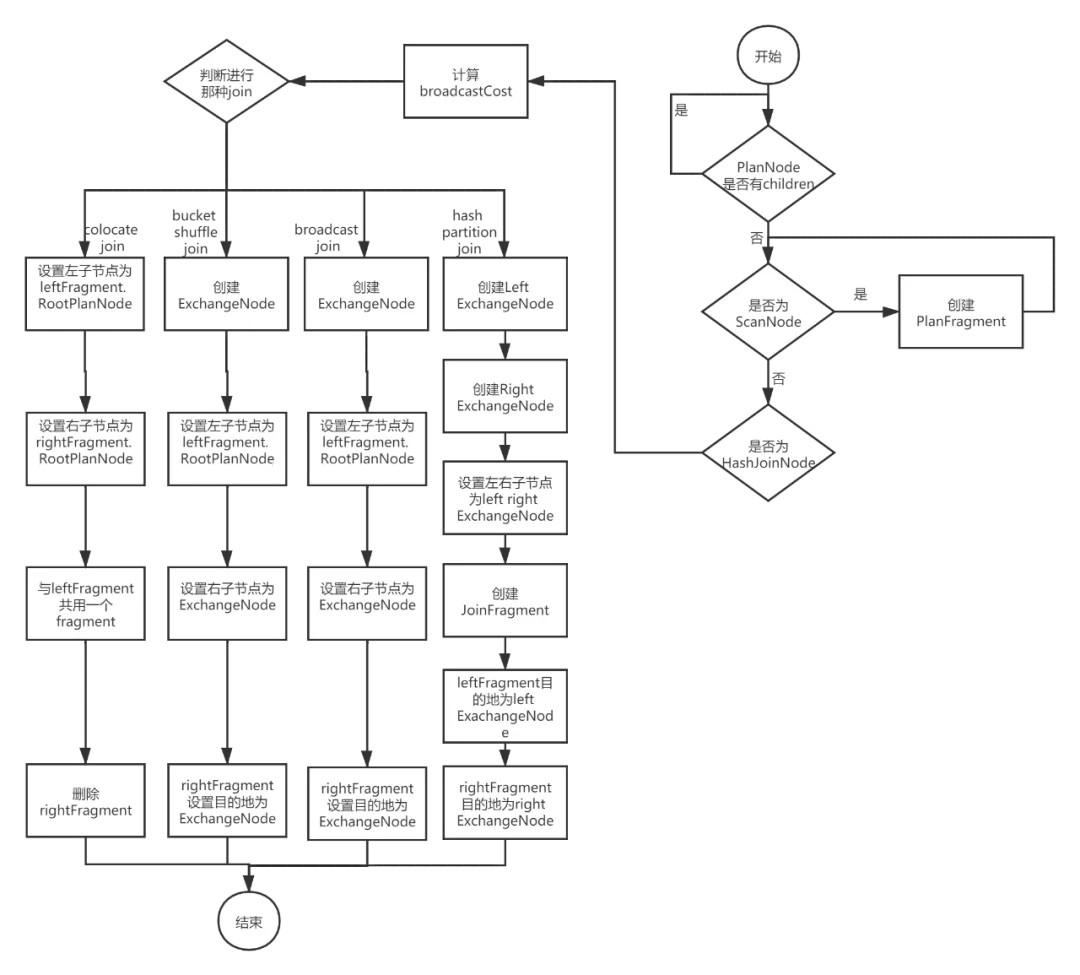
- 对PlanNode,自底向上创建PlanFragment。
- 如果是ScanNode,则直接创建一个PlanFragment,PlanFragment的RootPlanNode是这个ScanNode。
- 如果是HashJoinNode,则首先计算下broadcastCost,为选择boracast join还是hash partition join提供参考。
- 根据不同的条件判断选择哪种Join算法
- 如果使用colocate join,由于join操作都在本地,就不需要拆分。
设置HashJoinNode的左子节点为leftFragment的RootPlanNode,右子节点为rightFragment的RootPlanNode,与leftFragment共用一个PlanFragment,删除掉rightFragment。 - 如果使用bucket shuffle join,需要将右表的数据发送给左表。所以先创建了一个ExchangeNode, 设置HashJoinNode的左子节点为leftFragment的RootPlanNode,右子节点为这个ExchangeNode,
与leftFragment共用一个PlanFragment,并且指定rightFragment数据发送的目的地为这个ExchangeNode。 - 如果使用broadcast join,需要将右表的数据发送给左表。
所以先创建了一个ExchangeNode,设置HashJoinNode的左子节点为leftFragment的RootPlanNode, 右子节点为这个ExchangeNode,与leftFragment共用一个PlanFragment,并且指定rightFragment数据发送的目的地为这个ExchangeNode。 - 如果使用hash partition join,左表和右边的数据都要切分,需要将左右节点都拆分出去,分别创建left ExchangeNode, right ExchangeNode,HashJoinNode指定左右节点为left ExchangeNode和 right ExchangeNode。
单独创建一个PlanFragment,指定RootPlanNode为这个HashJoinNode。
最后指定leftFragment, rightFragment的数据发送目的地为left ExchangeNode, right ExchangeNode。
Schedule阶段
这一步是根据分布式逻辑计划,创建分布式物理计划。
主要解决以下问题:
- 哪个 BE 执行哪个 PlanFragment
- 每个 Tablet 选择哪个副本去查询
- 如何进行多实例并发
评论区